Mapping the Audio Landscape
for Innovative Music Sample Generation
Authors: Christian Limberg and Zhe Zhang
Abstract
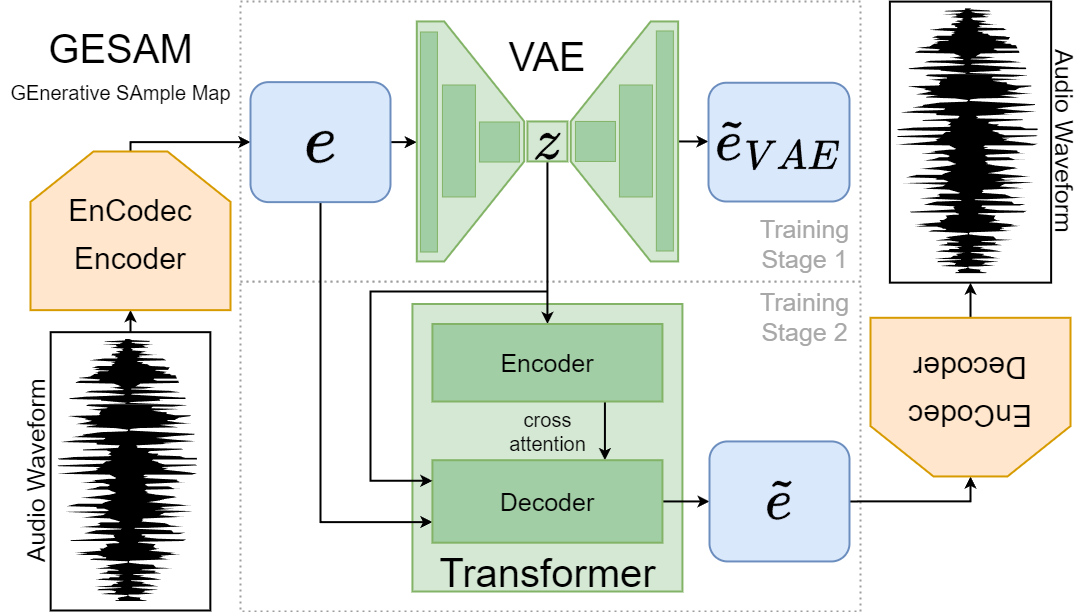
This paper introduces the Generative Sample Map (GESAM), a novel two-stage unsupervised learning framework capable of generating high-quality and expressive audio samples for music production. Recent generative approaches based on language models rely on text prompts as conditions. However, fine nuances in musical audio samples can hardly be described in the modality of text. For addressing this shortcoming, we propose to learn a highly descriptive latent 2D audio map by a Variational Autoencoder (VAE) which is then utilized for conditioning a Transformer model. We demonstrate the Transformer model's ability to achieve high generation quality and compare its performance against two baseline models. By selecting points on the map that compresses the manifold of the audio training set into 2D, we enable a more natural interaction with the model. We showcase this capability through an interactive demo interface, which is accessible on this website.
Audio Sample Generator
Cite Us
@inproceedings{10.1145/3652583.3657586,
author = {Limberg, Christian and Zhang, Zhe},
title = {Mapping the Audio Landscape for Innovative Music Sample Generation},
year = {2024},
isbn = {9798400706196},
publisher = {Association for Computing Machinery},
url = {https://doi.org/10.1145/3652583.3657586},
doi = {10.1145/3652583.3657586},
booktitle = {Proceedings of the 2024 International Conference on Multimedia Retrieval},
pages = {1207–1213},
keywords = {audio generation, audio visualization, generative models, transformer, user interfaces, variational autoencoder, visualization},
series = {ICMR '24}
}