Deep Detection Dreams: Enhancing Visualization Tools for Single Stage Object Detectors
Authors: Christian Limberg, Augustin Harter, Andrew Melnik, Helge Ritter, Helmut Prendinger
Abstract
This article introduces the DeepDream approach for object detection, which allows us to visualize how objects are represented in single stage object detector networks like YOLO. Such networks work by predicting objects for thousands of fixed image positions in parallel which makes them even more opaque compared to classification CNNs. While there has been much work on feature visualization for classification, this study examines how visualization methods can deal with the multitude of possible object positions in detection tasks and investigates the necessary adaptions of the DeepDream method. Our experiments suggest that YOLO detects objects relative to the scene composition. YOLO does not only recognize single objects but it also has a clear representation of scene context, object sub-types, positions, and orientations. We visualize our findings with interactive, web-based demo applications, which are available on our webpage. This research broadens the understanding of how objects are represented in object detection networks.
Figure 1: YOLOs Intermediate Grid Cell Detections

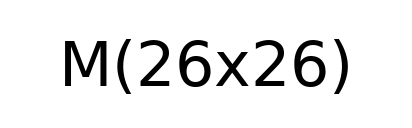
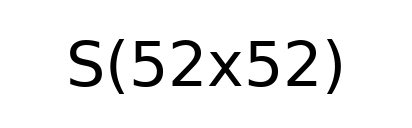






Figure 2: Grid Cells and their Confidences