YOLO - You only look once 10647 times
Authors: Christian Limberg, Andrew Melnik, Helge Ritter, Helmut Prendinger
published at VISIGRAPP 2023 conference
Abstract
In this work, we explore the You Only Look Once (YOLO) single-stage object detection architecture and compare it to the simultaneous classification of 10647 fixed region proposals. We use two different approaches to demonstrate that each of YOLO's grid cells is attentive to a specific sub-region of previous layers. This finding makes YOLO's method comparable to local region proposals. Such insight reduces the conceptual gap between YOLO-like single-stage object detection models, R-CNN-like two-stage region proposal based models, and ResNet-like image classification models. This page shows interactive exploration tools and exported media for a better visual understanding of the YOLO information processing streams.{kind=link}
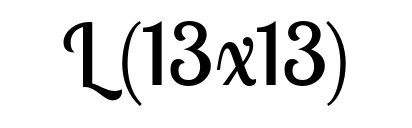
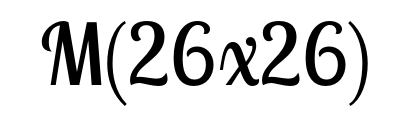







Figure 2
With our interactive visualization, the full grid layers of the YOLO.v4 network can be depicted for several images. The YOLO architecture has 3 different pathways for recognizing objects of different sizes. The recognition heads are located in 2d-grids of different resolutions. Each grid element can detect underlying objects based of 3 possible anchor box shapes. Each anchor box refines estimates of the x- and y-position, the width and the height, a confidence value and a probability vector of each class used for training. The bounding boxes are labeled with the predicted class, the certainty value and an index of the displayed anchor box (we depict only the most confident anchor box out of the 3 possible). Object proposals with a high certainty are colored blue. By the top bars, the pathway and the input image to be visualized can be selected. By hovering over the figure, the respective grid cell and the detected bounding box of the most certain anchor box is visualized.
Figure 3
Shifting the actual input image below the grid cells makes apparent how the confidences of the anchor boxes (blue means high confidence) are shifted and neighboring grid cells get activated. By the top button rows, the pathway and the input image to be visualized can be selected. By hovering over the figure, the input image is shifted.X
Y
Width
Height
Confidence
Probability (for class person)
Layer 75
Layer 103
Layer 104
Layer 105